AISmarteasy – 시맨틱 커널 포크로 개발하기 1 – 시작
Microsoft에서 오픈소스로 개발 중인 Semantic-Kernel을, 입맛대로 다시 개발해 보고 있다. 여러 명이 협업해서 어느 정도 개발이 되었으니, 이걸 기반으로 혼자 빠르게 원하는 대로 바꿔가고자 한다. 시맨틱 커널은 기본 틀은 대부분 되었지만, 여전히 소스 코드 수준에서 매우 빠르게 변하고 있다. 시간이 지남에 따라 변경도 추적해 나가면서 변화의 추이를 살펴볼 필요도 있다.
개발도 중요하지만, 내용 정리도 중요하다. 개발 과정에서 정리할 내용들을 정리하고 공유하려고 한다. 개발되는 레파지토리는 깃헙에 공개한다. 깃헙 smarteasy 계정으로. https://github.com/smarteasy/
개발을 영리하게 그렇지만 조금 쉽게 하자는 의미로 깃헙 아이디를 smarteay로 하고 있다. AI 애플리케이션도 좀 더 영리하고 쉽게 하자는 의미로 AISmarteasy로 한다. 최종 적으로 이 레파지토로 모든 소스가 합쳐지겠지만, 과정 중에는 여러 레파지토리들이 등장할 수 있다.
그런데 시맨틱 커널이 뭐야?
아래 링크에 자세히 잘 설명되어 있다.
https://learn.microsoft.com/en-us/semantic-kernel/
이 내용을 잘 읽어보고 자기의 말로 잘 설명해 보자.
전체적으로 내용을 잘 이해했다고 생각되는 시점에서 아래 내용과 그림을 설명해 보자. 잘 안되면 잘 안되는 부분을 다시 잘 읽어보고 다시 설명 가능한지 확인해 보기를 반복해 보자.
Semantic Kernel is an open-source SDK that lets you easily combine AI services like OpenAI, Azure OpenAI, and Hugging Face with conventional programming languages like C# and Python. By doing so, you can create AI apps that combine the best of both worlds.
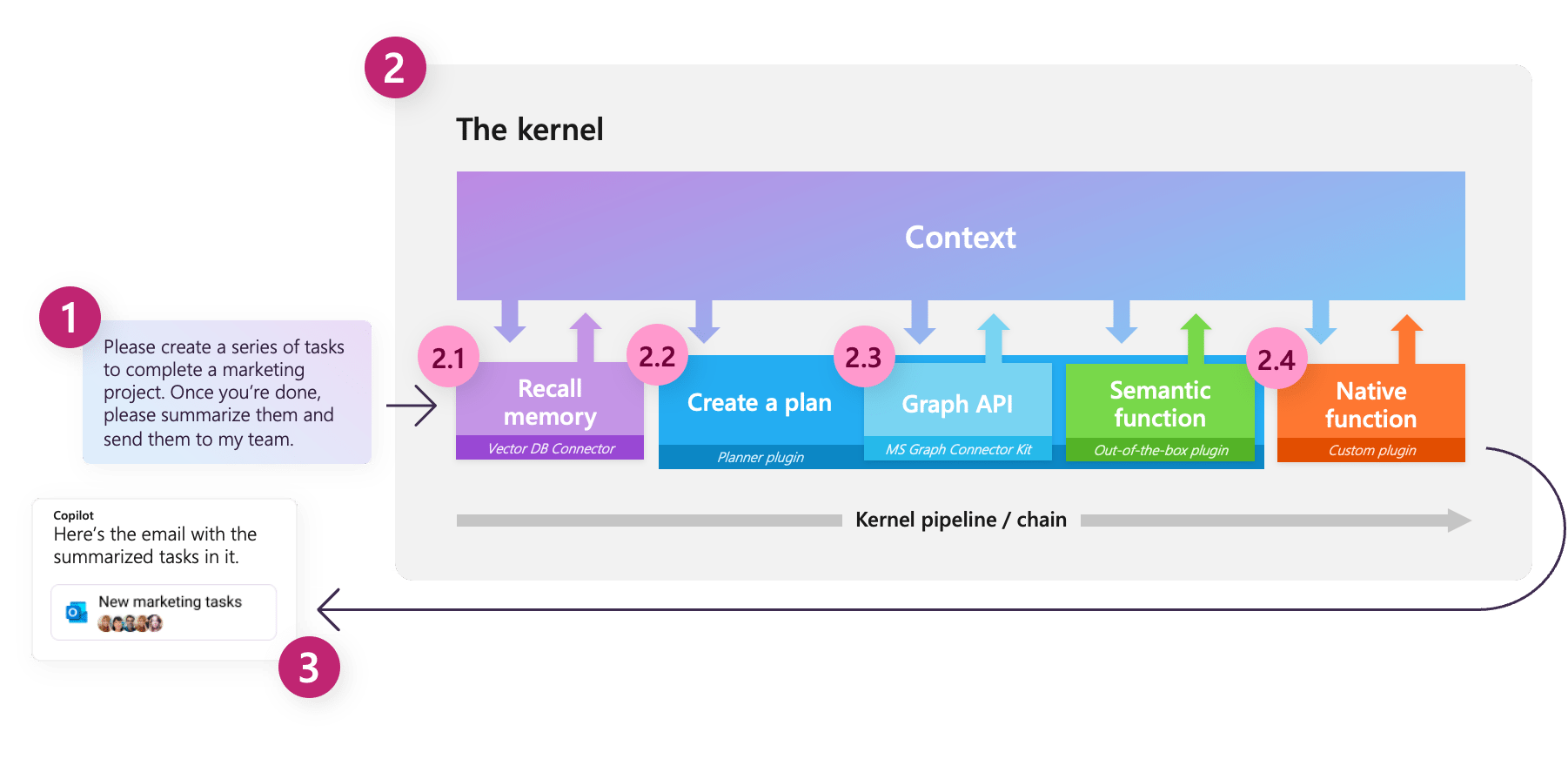
시맨틱 커널은 Microsoft가 주도해 개발하고 있다. LLM(Large Language Model – AI 모델) 연동 AI 애플리케이션 개발을 위한 오픈소스 개발 프레임워크이다.
Microsof가 OpenAI에 큰 투자를 할 정도로 AI에 큰 변화가 일고 있다. Microsof는 윈도우와 오피스를 등장시켰던 것 같이 AI 타기를 잘 하고 있다. 다양한 제품들 뿐만 아니라 클라우드인 애저도 큰 변화가 있다. 요즘 Microsof의 움직임은 심상치 않다. 시맨틱 커널도 Microsof가 주도하고 있다.
LLM과 같은 AI 모델을 만드는 것은 돈도 많이 들고 시간이 많이 걸린다. 돈이 많이 들기 때문에 돈이 많은 애들이 할 수 밖에 없다. 한 번 대장이 되면 특별한 일이 생기지 않으면 계속 대장을 해 먹을 확률이 높다. LLM은 OpenAI가 대장이고 이 자리에 오래 눌러 앉을 것 같다. Microsof도 그렇게 판단했으니 큰 돈을 투자했겠지.
그럼 그럴만한 돈도 시간도 없는 애들은? 거인 어깨에 올라타야 한다. AI 모델은 못 만드니 대장 AI 모델과 연동되는 AI 애플리케이션을 개발하면 된다. 부실한 어깨에 올라타려면 용기가 필요하다. 탔다가 털어지면 골병 든다.
시맨틱 커널은 이를 지원하기 위해 등장했다. 오픈소스로 파이썬으로 개발되고 있는 랭체인도 같은 포지션이다. 우리도 처음에는 랭체인에 올인. 지금 AI 애플리케이션 개발은 미국 서부시대 때와 비슷하다고 보고, 주도하는 세력이 기업인 시맨틱 커널로 옮겼다. 파이썬 보다 C#을 더 좋아하기도 하고. 랭체인은 파이썬만 지원하고 있다. 앞으로 어떻게 될 지 모르지만.
LLM 연동 AI 애플리케이션 개발에 포지셔닝 했다면, 누구 어깨에 올라 탈 지가 중요하다. LLM에서 가장 강한 어깨를 가진 거인은 현재 1등인 OpenAI(이건 결국 마이크로소프트라 보고). AI 기존 강자인 구글, 오픈 소스 세력 쪽에 있는 메타 어깨도 잘 살펴야 한다. 애국심이 없는 것도 아니고 약한 자의 편에 서고도 싶지만 개발자로서 여럿 한 다는 것은 귀찮다. 우선 시맨틱 커널이 중요하게 다루는 OpenAI의 어깨에 타고 놀다가. 1등 자리에 오를 것 같기도 하고, 개발 요청이 많은 거인이 생기면, 그 어깨에 타고 노는 게 기존과 크게 차이가 없다면, 갈아 탈지 고민해 볼 것 같다.
Microsof가 개발 도구를 만드는 회사이기도 하니, AI 애플리케이션 개발이 주가 될 것을 봤다면, 이를 위한 개발을 하는 것은 당연하다. 이미 코파일럿이라는 개념도 가지고 있었으니 코파일럿 개발 도구로 포지셔닝 하면 된다. 앞으로 개발자들은 시맨틱 커널과 같은 AI 애플리케이션 개발 프레임워크를 잘 사용하는 것이 중요한 개발 역량이 될 것 같다.
Microsof에 본질을 개념화하고 그것에 멋진 이름을 붙이는 뛰어난 인재가 있나 보다. AI를 코파일럿으로 개념화하고, 지금의 AI 애플리케이션 흐름의 본질을 Semanctic으로 개념화 하다니. 박수를 보낸다.
Microsof는 이전부터 AI를 Copilot으로 자리매김하고 있다. Copilot, AI는 너무 조심해야 할 대상도 그렇다고 너무 의존할 대상도 아니라는 거다. LLM도 AI Service라고 하고 있다. 서비스이니 클라우드에서 제공 되는 게 좋겠지. 애저도 중요한 역할을 할 것이란 거다.
시맨틱 커널은 OpenAI의 GPT와 같은 LLM과 연동하는 AI 애플리케이션 개발 지원을 위해 등장했으니 프롬프트가 중요하다. 프롬프트를 다루는 부분으로 개발을 시작할 거다.
시맨틱 커널은 AI 애플리케이션의 기능을 구현하는 최하위 단위를 함수(function)라고 한다. 함수는 LLM에 전달할 프롬프트로 작성된 시맨틱 함수(semantic function)와, 기존 SW 방식으로 개발되는 함수를 네이티브 함수(native function)라 한다. 그리고 함수들을 한 묶음으로 관리하기 위한 개념을 플러그인(plugin)이라고 한다. 이전에는 스킬 이라 했는데, 개인적으로 플러그인 보다 스킬이 좋다.
시맨틱 함수는 LLM 연동을 위한 부분으로(프롬프트에 해당하는 부분), LLM 연동 AI 애플리케이션 개발의 핵심이다. 네이티브 함수는 시맨틱 함수 만으로 부족한 부분을 채우기 위한 것 – LLM은 태생적 한계가 있는데 이를 보완하기 위한 것 – 이런 부분이 없어지면 필요 없게 되겠지 – 이다. 프롬프트의 부분들이 네이티브 함수의 결과로 채워진다.
결국 LLM 연동 AI 애플리케이션은 LLM에게 전달될 지시에 해당하는 내용인, 프롬프트 작성을 위해 필요하다. 이를 위해 등장한 것이 시맨틱 커널 이다. LLM의 태생적 한계로 인해 부족한 데이터를 채워주기 위한 공통의 기능을 제공한다.
프롬프트를 다루는 부분 개발 다음은 시맨틱 함수와 네이티브 함수를 다루는 PluginFunction을 할 것이다.
네이티브 함수로 작성될 것들에는 뭐가 있을까?
AI 모델 LLM은 훈련 시점이 있고 훈련에 사용된 데이터들이 있다. 시점이 있기 때문에, 그 시점 이후에 만들어진, 새로운 정보나 지식을 담고 있는 데이터의 내용은 모르고, 그 시점 이전에 만들어진 데이터라도 접근 할 수 없다면 당연히 모른다. 이런 데이터들에 접근할 수 있는 방법이 필요하다.
훈련 시점 이후 공개된 데이터는 구글과 같은 검색 엔진을 통해 구할 수 있다.
LLM이 접근할 수 없는 데이터 중, 기업들의 데이터는 대부분 기업의 데이터베이스, 기술적으로는 관계형 데이터베이스에 있을 것이다. 관계형 데이터베이스를 검색해서 프롬프트 부분을 채우면 된다고 생각할 수 있다. 그럴 수 있다. 문제는 OpenAI의 ChatGPT가 등장하면서, LLM과 상호작용 하는 방법을 자연어로, 사람과 대화하듯 하는 방식을 선 보였고 사용자들은 이런 방식을 좋아해서, 이렇게 되지 않는 것은 쳐다 보지도 않을 것이라는 거다.
그러다 보니 자연어로 쿼리 가능한 벡터 데이터베이스가 등장했다. LLM 연동 AI 애플리케이션은 사용자 데이터를 벡터화 해서 벡터 데이터베이스에 저장하고 검색 할 수 있어야 한다.
기업 데이터는 관계형 데이터베이스 말고도 다양한 형식의 문서들에 담겨 있을 수 있다. 이들도 벡터화 할 수 있어야 한다.
기업 데이터는 데이터를 작성한 데스크탑 애플리케이션들이나 웹 서비스들 만을 통해 접근해야 할 수 도 있다. 이들에 접근할 수도 있어야 한다. 더 이상 사용하지 않는다고 하면 벡터화해서 벡터 데이터베이스로 접근하면 되지만, 그렇지 않다면 이들에 접근할 수 있는 기능이 개발되어야 한다. 기존의 서비스에 연결할 수 있어야 한다. AI 서비스에 연결하든, 기존 서비스에 연결하든 거기에 연결해야 하므로 Connector.
Connector를 호출하는 것은 결국 함수니, 이와 관련된 네이티브 함수를 작성해야 한다. 이런 네이티브 함수는 일반적인 것이 아닌 구글 검색과 같은 커넥터를 사용하는 구체적인 것이 된다. 개발 시, 일반(추상)과 구체가 있다면, 구체는 그걸 하는 대상에 따라 추가되거나 변경되기 때문에, 일반과 구체 코드들을 구분해서 개발해야 한다.
PluginFunction을 다룬 개발 다음 이 부분을 다룰 것이다. 기존 기능에 연결할 수 있는 것으로 Connector 개발. 커넥터는 서비스에 연결하는 거니 Service로 묶자.
LLM이 할 일을 프롬프트로 잘 지시할 수 있다면 문제는 여기서 끝난다. 하지만 만족할 만한 결과를 낼 수 있는 프롬프트 작성은 쉽지 않다. 뭘 하라고 지시만 하면, LLM 연동 AI 애플리케이션이 알아서 LLM과 어떻게 상호작용 할 지를 계획하고 그 계획대로 해서 지시한 결과를 얻을 수 있다면 좋을 것이다.
Connector 개발 이후, 목표 수준의 지시를 달성하기 위해 계획을 세우고 실행하는 기능을 개발할 것이다. Planner.
시맨틱 커널은 단일 함수로 계획하고 실행하는 ActionPlanner와, 다수의 함수가 순차적으로 실행될 수 있도록 계획하고 이를 순차적으로 실행하는 SequentialPlanner와 점진적으로 목표 달성할 수 있도록, 목표를 달성할 때까지 계획하고 실행하고, 이전 단계의 실행 결과를 보고 다시 계획하고 실행을 반복하는 StepwisePlanner를 제공한다.
비용에 대한 고려가 없다면 플래너에서 끝내면 된다. 하지만 LLM과 연동은 서비스 개념으로 자주 주고 받는 내용이 많으면 돈을 많이 내야 한다. 비용을 생각해서 플래너를 사용할 것인지 플래너 외의 기능들을 조합할 지를 결정해야 한다.
플래너를 사용하지 않는 다면 그 것을 할 수 있는 기능을 개발해야 한다. 그건 결국 시맨틱 함수나 네이티브 함수로 개발된다. 커넥터들과 함수들이 협력하도록 하는 함수.
Planner 개발 이후, 커넥터와 함수들을 협력하도록 하는 Worker를 개발할 것이다. AI 애플리케이션은 AI 서비스들을 사용해 작업하는 거니.
작업자는 프롬프트로 llm에게 직접 지시할 수도 있고, 목표를 주고 계획을 세워 실행하도록 할 수도 있다. InstructionWorker와 PlannerWorker. 목표를 받아 달성하는 AI 애플리케이션을 Agent라 하니 PlannerWorker는 Agent라는 이름으로 바뀔 수 있다.
LLM은 훈련된 데이터의 한계에 갇히기 때문에, LLM 연동 AI 애플리케이션은 새로운 데이터를 기억하는 게 중요해 진다. 기억할 것에는 단기로 기억하면 되는 게 있고 장기로 기억해야 할 것이 있다. Memory 등장.
기억은 작업자가 작업을 할 때 필요하니, Worker 개발할 때 Memory도 개발하기로 한다. 자연어로 다뤄질 것이니, 기억 데이터는 임베딩 되어 벡터가 되어야 한다.
단기 기억은 필요 할 때만 기억하면 되는 휘발성 데이터이다. 장기 기억은 파일이나 관계형 데이터베이스를 필요로 할 수 있다. 최적의 장기 기억 수단은 벡터 데이터베이스. 대표적인 벡터 데이터베이스 파인콘 정도를 지원하기로 한다. 메모리나 파일이나 관계형 데이터베이스를 사용할 수도 있다. 데이터를 저장하는 방식이 다양하니 공통 개념으로 MemoryStore 를 사용하자.
LLM 연동 AI 애플리케이션은 LLM의 특성이나 한계에 따라,
프롬프트 관련된 것들이 처음 등장하고, LLM의 태생적 한계를 보충할 것들이 등장하고, 목표 수준의 일을 시킬 수 있는 것이 등장한다. 그 다음은? 우리는 의미를 전달하는 수단이 텍스트에서 음성과 이미지와 비디오로 확장된다고 본다. 그 다음은 하드웨어 쪽으로 가겠지. 하드웨어 쪽으로 간 뒤에는 로봇과 사람의 협업 쪽으로 가겠지. 기본적인 방향은 필요에 의해서 정해졌다. 그 다음은?
[기능 요구]
llm 벤더들이 제공하는 ai 서비스가 돌아가도록 한다.
[비기능 요구]
llm 벤더 제공 ai 서비스들이나 llm의 한계를 보완하기 위해 사용되는 서비스들이 보통 실행 시간을 좀 요구하니 비동기와 streaming 방식으로 데이터를 주고 받는 것이 기본이어야 한다.
외부 서비스에 의존하니 서비스 제공에 대한 로그나 상태를 모니터링 할 수 있어야 한다.
[개발 환경]
1. Visual Studio 2022에서 C#으로 개발 한다.
2. 윈도우 10이상에서 실행되는 것을 기본으로, 향후 맥os에서도 실행되도록 한다.
[코딩 컨벤션]
1. 열거형(enum) 이름 작성할 때, 접미사로 Kind를 사용한다.
2. 주석은 가능 한 작성하지 않는다. 코드가 말하게 하라.
소프트웨어 기능을 위한 구성요소 들의 상호작용에도 자연어를 사용할 수 있도록 개발 프레임워크가 지원한다면, 소프트웨어는 소프트웨어 외부 요소들과도, 내부 요소들 사이에서도 상호작용은 자연어로만 하게 된다. 이 부분 개발도 공통 부분이 된다는 것이다.