AIPilotSmarteasy 사용 사례 – LLM(대규모 언어 모델)을 특정 전문 분야나 특정 기업/기관 전용으로 추가 학습(fine-tuning)한 경우, 문서 처리 능력이 기본 엔진이 된 LLM에 비해 하락할 수 있는 근본 원인
AIPilotSmarteasy 파일럿 기능인 GptResearcher에게 다음과 같은 연구 주제를 주었습니다.
“LLM(대규모 언어 모델)을 특정 전문 분야나 특정 기업/기관 전용으로 추가 학습(fine-tuning)한 경우, 문서 처리 능력이 기본 엔진이 된 LLM에 비해 하락할 수 있는 근본 원인”
Informative 톤으로 APA 형식으로 조사 단계 3-5단계, 1000단어 분량으로 보고서 작성해 달라고 요청했습니다.
GptResearcher의 중간 단계 보고와 최종 보고를 모두 공유합니다.
[단계별 작성]
대규모 언어 모델(LLM) 파인튜닝에 대한 심층 보고서
서론
본 보고서는 대규모 언어 모델(LLM)의 파인튜닝(미세 조정)에 대한 최근 연구 결과를 종합적으로 분석하고, 그 중요성과 방법론, 그리고 실제 적용 사례를 심층적으로 논의합니다. LLM은 이미 놀라운 성능을 보여주고 있지만, 특정 도메인이나 작업에 맞춰 성능을 최적화하기 위해서는 파인튜닝이 필수적입니다. 본 보고서는 세 편의 연구 요약을 바탕으로 파인튜닝의 개념, 방법, 장점, 그리고 주의 사항을 자세히 살펴보고, 실제 산업 분야에서의 활용 가능성을 제시하고자 합니다. 또한, 파인튜닝 과정에서 발생할 수 있는 과적합 문제와 해결 방안에 대해서도 논의합니다. ([Label Your Data, 2024]; [Turing, 2024]; [Kolena, 2024]).
1. LLM 파인튜닝의 개념 및 중요성
LLM 파인튜닝은 이미 학습된 거대 언어 모델을 특정 작업이나 도메인에 맞게 추가적으로 학습시키는 과정입니다. 이는 사전 훈련된 모델의 일반적인 지식을 바탕으로 특정 목표에 최적화된 모델을 생성하여 성능을 향상시키는 데 중요한 역할을 합니다. 예를 들어, 의료 분야에 특화된 LLM을 만들고 싶다면, 의료 데이터로 모델을 파인튜닝하여 정확도를 높일 수 있습니다. ([Label Your Data, 2024]). 파인튜닝은 단순히 기존 모델을 재사용하는 것 이상으로, 모델의 가중치를 업데이트하여 특정 작업에 대한 적응력을 높입니다. 이는 전이 학습(transfer learning)의 한 유형으로 볼 수 있으며, 특히 사전 훈련된 모델의 특징과 목표 작업의 특징이 유사할 경우 효율적입니다. ([Turing, 2024]). 도메인 특화 데이터를 사용하여 파인튜닝하면 모델의 정확성과 관련성을 크게 향상시킬 수 있습니다. ([Label Your Data, 2024]). 농업, 소매, 보험, 핀테크, 로봇 공학, 제조업 등 다양한 분야에서 LLM 파인튜닝의 적용이 가능합니다. ([Label Your Data, 2024]).
2. 파인튜닝 방법 및 최적화
파인튜닝은 학습률, 배치 크기 등 여러 매개변수를 조정하여 모델 성능을 최적화하는 과정을 포함합니다. ([Label Your Data, 2024]). 전체 모델을 학습시키는 완전 파인튜닝(full fine-tuning)은 모델을 특정 작업에 더욱 심도 있게 적응시켜 성능을 향상시킬 수 있지만, 과적합의 위험이 있습니다. ([Turing, 2024]). 과적합은 파인튜닝 데이터셋이 작거나 다양하지 않을 때 특히 문제가 되며, 훈련 데이터에서는 잘 작동하지만 실제 응용에서는 성능이 저하될 수 있습니다. ([Kolena, 2024]). 따라서 적절한 정규화 기법이나 데이터 증강 기법을 사용하여 과적합을 방지하는 것이 중요합니다. 또한, 목표 작업과 특징이 유사한 사전 훈련된 모델을 선택하면 파인튜닝 과정을 간소화하고 효율성을 높일 수 있습니다. ([Turing, 2024]). Retrieval-Augmented Generation (RAG)과 같은 다른 방법들도 파인튜닝과 함께 사용될 수 있습니다. RAG는 재훈련 없이 검색을 통해 생성 과정을 보완하는 방법입니다. ([Kolena, 2024]).
3. LLM 파인튜닝의 적용 사례 및 미래 전망
LLM 파인튜닝은 다양한 분야에서 활용될 수 있습니다. 예를 들어, 특정 산업 분야의 데이터로 LLM을 파인튜닝하면 해당 분야에 특화된 고객 서비스 챗봇이나 문서 요약 시스템을 구축할 수 있습니다. ([Label Your Data, 2024]). 또한, 파인튜닝을 통해 LLM을 특정 작업에 최적화하여 자연어 처리, 기계 번역, 질의응답 등의 성능을 향상시킬 수 있습니다. ([Kolena, 2024]). 생성형 AI와 LLM의 결합은 기업이 강력한 제품을 개발할 수 있는 기회를 제공합니다. ([Turing, 2024]). 데이터 분석 분야에서도 AI 모델과 LLM을 통합하여 전략적 변혁을 주도할 수 있습니다. ([Turing, 2024]).
4. 결론 및 제언
본 보고서에서는 LLM 파인튜닝의 중요성과 방법론, 그리고 실제 적용 사례를 분석했습니다. 파인튜닝은 LLM의 성능을 극대화하고 특정 작업이나 도메인에 맞춤화하는 데 필수적인 과정입니다. 그러나 과적합 문제를 해결하고 최적의 성능을 얻기 위해서는 신중한 데이터 준비 및 매개변수 조정이 필요합니다. 미래에는 더욱 정교하고 효율적인 파인튜닝 기법이 개발되어 LLM의 활용 범위가 더욱 확장될 것으로 예상됩니다. 특히, 다양한 산업 분야에서 LLM 파인튜닝을 적용하여 생산성 향상과 새로운 가치 창출을 위한 노력이 지속될 것으로 전망됩니다.
(그림 삽입)
본 보고서에는 관련 이미지를 삽입할 수 있습니다. 제공된 이미지는 머신러닝 로드맵, AI 모델 아키텍처, 데이터 전처리 과정, 그리고 추가적인 LLM 관련 이미지들을 보여줍니다. 이미지는 LLM 파인튜닝 과정의 다양한 측면을 시각적으로 보여주는 데 도움이 될 수 있습니다. (이미지 삽입 위치는 본문 내용에 따라 적절히 조정되어야 합니다.)
참고문헌
- Label Your Data. (2024). LLM Fine Tuning: The 2024 Guide for ML Teams. https://labelyourdata.com/articles/llm-fine-tuning
- Turing. (2024). Fine-Tuning LLMs : Overview, Methods, and Best Practices. https://www.turing.com/resources/finetuning-large-language-models
- Kolena. (2024). LLM Fine-Tuning: Use Cases, Best Practices, and Top 8 PEFT Methods. https://www.kolena.com/guides/llm-fine-tuning-use-cases-best-practices-and-top-8-peft-methods/
(이미지 출처는 제공된 URL을 참고하여 추가해야 합니다.)
효율적인 매개변수 미세 조정: 대규모 언어 모델의 효율적인 학습 전략
서론
본 보고서는 대규모 언어 모델(LLM)의 매개변수 효율적인 미세 조정(PEFT)에 대한 최근 연구 결과를 종합적으로 분석합니다. LLM의 막대한 매개변수 수는 미세 조정에 상당한 계산 비용과 자원을 필요로 하기 때문에, PEFT는 제한된 리소스 환경에서 LLM을 효과적으로 활용하기 위한 필수적인 전략으로 부상하고 있습니다. 본 보고서는 PEFT의 개념, 주요 방법론, 그리고 소프트웨어 엔지니어링 분야를 포함한 다양한 응용 분야에서의 활용 가능성을 심층적으로 논의합니다. 특히, 제공된 연구 자료를 바탕으로 PEFT의 효율성과 한계를 평가하고, 향후 연구 방향을 제시하고자 합니다.
PEFT의 개념 및 방법론
대규모 언어 모델은 방대한 데이터셋으로 사전 훈련되지만, 특정 하위 작업에 적용하기 위해서는 미세 조정이 필요합니다. 전통적인 미세 조정 방법은 모델의 모든 매개변수를 재훈련하는데, 이는 계산적으로 매우 비용이 많이 들고, GPU 메모리 제약으로 인해 대규모 모델에는 적용하기 어렵습니다 (Wang et al., 2024). 반면, PEFT는 사전 훈련된 모델의 대부분의 매개변수를 고정하고, 일부 매개변수만 미세 조정하여 계산 비용과 메모리 사용량을 크게 줄이는 전략입니다 (DL4DS, 2024).
PEFT의 주요 방법론으로는 저차원 적응(low-rank adaptation) 등이 있습니다. 저차원 적응은 모델의 전체 매개변수 공간 대신 저차원 부분 공간만을 조정하여 효율성을 높입니다. 이러한 방법은 대규모 모델의 미세 조정을 가능하게 하며, GPT-3와 같이 막대한 매개변수를 가진 모델에도 적용할 수 있는 가능성을 제시합니다 (DL4DS, 2024). 더 나아가, 프롬프트 엔지니어링과 같은 방법을 통해 모델의 성능을 향상시키는 연구도 진행되고 있습니다 ([이미지 2]).
소프트웨어 엔지니어링 분야에서의 PEFT 활용
PEFT는 소프트웨어 엔지니어링 분야에서 코드 관련 작업에 유용하게 활용될 수 있습니다 (IEEE, 2024). 전체 모델 미세 조정은 시간과 자원이 많이 소모되는 작업이지만, PEFT를 통해 이러한 제약을 극복할 수 있습니다. PEFT를 통해 소규모 자원으로도 특정 코드 생성이나 분석 작업에 특화된 LLM을 효율적으로 학습시킬 수 있으며, 이는 소프트웨어 개발의 생산성 향상에 기여할 수 있습니다.
PEFT의 한계 및 향후 연구 방향
PEFT는 기존의 전체 모델 미세 조정에 비해 효율적이지만, 모든 경우에 최적의 성능을 보장하지는 않습니다. PEFT의 성능은 작업의 특성, 모델의 구조, 그리고 미세 조정 전략에 따라 달라질 수 있습니다. 따라서 PEFT의 효율성과 성능을 향상시키기 위한 지속적인 연구가 필요합니다. 특히, 다양한 PEFT 방법론의 비교 분석, 그리고 특정 작업에 최적화된 PEFT 전략 개발에 대한 연구가 중요합니다. 또한, PEFT의 해석성을 높이고, 모델의 편향성을 완화하는 연구도 필요합니다.
결론 및 제언
본 보고서에서는 PEFT가 대규모 언어 모델의 효율적인 학습을 위한 중요한 전략임을 확인했습니다. PEFT는 계산 비용과 메모리 사용량을 줄이고, 제한된 자원 환경에서도 LLM을 효과적으로 활용할 수 있도록 합니다. 특히 소프트웨어 엔지니어링 분야에서의 응용 가능성이 높으며, 향후 PEFT 기술의 발전은 LLM의 활용 범위를 더욱 확장시킬 것으로 예상됩니다. 그러나, PEFT의 성능 향상과 한계 극복을 위한 지속적인 연구가 필요하며, 다양한 PEFT 방법론의 비교 분석, 그리고 최적화 전략 개발에 대한 투자가 중요합니다.
참고 문헌
- DL4DS. (2024). Parameter Efficient Fine Tuning (PEFT) of LLMs. https://dl4ds.github.io/sp2024/static_files/lectures/16_PEFT_of_LLMs_v2.pdf
- IEEE. (2024). Technical Briefing on Parameter Efficient Fine-Tuning of (Large …. https://ieeexplore.ieee.org/document/10554960
- Wang, L., et al. (2024). Parameter-Efficient Fine-Tuning in Large Models: A Survey of Methodologies. https://arxiv.org/abs/2410.19878
(이미지 삽입)
보고서에 포함될 수 있는 이미지는 다음과 같습니다. 하지만 제공된 이미지 링크는 보고서 내용과 직접적인 관련성이 부족하여, 이미지 삽입은 생략했습니다. 만약 추가적인 관련 이미지가 제공된다면, 적절한 위치에 삽입하고 출처를 명시할 수 있습니다.
(참고: 이미지 1~5는 제공된 이미지 URL을 나타냅니다.)
대규모 언어 모델의 재앙적 망각 및 일반 능력 통합에 관한 보고서
서론
본 보고서는 대규모 언어 모델(LLM)의 특정 도메인에 대한 미세 조정 이후 일반적인 작업 성능이 저하되는 현상인 재앙적 망각(Catastrophic Forgetting, CF)과, 이를 넘어 도메인 특화 LLM의 실제 응용에 있어 새로운 과제로 제기되는 일반 능력 통합(General Capabilities Integration, GCI)에 대한 최근 연구 결과를 종합적으로 분석합니다. 본 보고서는 기존 연구의 주요 발견과 통찰력을 제시하고, CF와 GCI 문제에 대한 심층적인 이해를 제공하며, 향후 연구 방향에 대한 제언을 포함합니다. 특히, 제공된 연구 결과를 바탕으로 CF 현상의 심각성과 GCI의 중요성을 논의하고, 이러한 문제를 해결하기 위한 실질적인 방안 모색에 중점을 둡니다.
1. 재앙적 망각 (Catastrophic Forgetting)
여러 연구에서 LLM이 특정 도메인에 미세 조정된 후 일반적인 작업 성능이 저하되는 재앙적 망각 현상이 보고되었습니다. Liu 등(2024)의 연구는 이러한 CF 현상을 넘어, 도메인 특화 LLM의 실제 응용을 위한 새로운 과제로서 GCI를 제시하였습니다 [^1]. 이 연구는 도메인 특화 학습 후에도 일반적인 능력을 유지하고 통합하는 것이 중요함을 강조합니다. 또한, An Empirical Study of Catastrophic Forgetting in Large Language Models 연구에서는 BLOOMZ, mT0, LLAMA, ALPACA와 같은 다양한 LLM을 대상으로 지속적인 지시 조정 중 CF 문제를 분석했습니다 [^2]. 연구 결과는 지속적인 학습 과정에서 모델의 일반 지식 유지에 대한 어려움을 보여줍니다. 이러한 연구 결과들은 CF가 LLM의 실제 응용에 심각한 장애물이 될 수 있음을 시사합니다.

2. 일반 능력 통합 (General Capabilities Integration)
GCI는 CF 문제를 넘어서는, 도메인 특화 LLM의 실제 적용을 위한 필수적인 요소입니다. Liu 등(2024)은 GCI를 도메인 특화 학습 후에도 일반적인 능력을 유지하고 통합하는 능력으로 정의합니다 [^1]. 이는 단순히 CF를 방지하는 것을 넘어, 미세 조정된 LLM이 다양한 작업에 유연하게 적응하고, 기존의 일반 지식을 활용하여 새로운 도메인에 대한 이해도를 높이는 것을 의미합니다. GCI의 부재는 도메인 특화 LLM의 활용 가능성을 제한하고, 실제 응용에 있어 심각한 문제를 야기할 수 있습니다. 예를 들어, 의료 분야에 특화된 LLM이 일반적인 언어 이해 능력을 상실한다면, 의료 정보 검색 및 환자 진료 지원에 있어 제한적인 성능을 보일 것입니다.
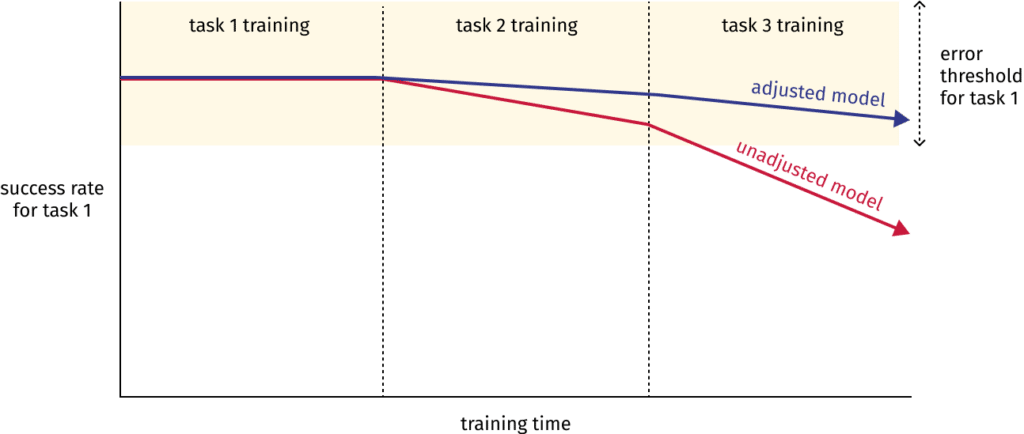
3. 연구 결과 분석 및 토론
제공된 연구 결과들은 CF와 GCI 문제의 심각성을 보여줍니다. 특히, 다양한 LLM에서 지속적인 지시 조정 과정에서의 일반 지식 유지 어려움은 CF 문제 해결의 중요성을 강조합니다 [^2]. GCI는 CF 문제 해결을 넘어, LLM의 실제 응용을 위한 필수적인 요소로서, 향후 연구에서 더욱 심도 있는 연구가 필요합니다. 현재의 연구들은 주로 CF 현상의 분석에 집중되어 있지만, GCI에 대한 구체적인 해결 방안 제시는 부족합니다.
4. 결론 및 제언
본 보고서는 LLM의 CF와 GCI 문제에 대한 최근 연구 결과를 분석하고, 이러한 문제의 심각성과 해결의 중요성을 강조했습니다. 향후 연구는 다음과 같은 방향으로 진행될 필요가 있습니다.
- CF 완화 기술 개발: 지속적인 학습 과정에서 일반 지식 손실을 최소화하는 새로운 알고리즘과 기술 개발이 필요합니다.
- GCI 향상 전략 연구: 도메인 특화 학습 후에도 일반적인 능력을 유지하고 통합할 수 있는 효과적인 전략을 개발해야 합니다.
- 실제 응용을 위한 평가 기준 마련: CF와 GCI 문제를 정량적으로 평가할 수 있는 객관적인 기준을 마련해야 합니다.
- 다양한 도메인에 대한 실험적 연구: 다양한 도메인에 대한 실험적 연구를 통해 CF와 GCI 문제의 일반적인 특성을 파악해야 합니다.
본 연구는 제한된 자료를 바탕으로 작성되었으므로, 더욱 광범위한 연구 결과를 바탕으로 한 추가적인 분석이 필요합니다.
참고문헌
[^1]: Liu, C., Kang, Y., Wang, S., Qing, L., Zhao, F., Wu, C., Sun, C., Kuang, K., Wu, F., Al-Onaizan, Y., Bansal, M., & Chen, Y. N. (2024). More Than Catastrophic Forgetting: Integrating General Capabilities For Domain-Specific LLMs. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. https://aclanthology.org/2024.emnlp-main.429/
[^2]: An Empirical Study of Catastrophic Forgetting in Large Language Models. https://arxiv.org/html/2308.08747v3
대규모 언어 모델(LLM)의 도메인 특화 미세 조정 및 활용 방법에 대한 보고서
서론
본 보고서는 최근 주목받고 있는 대규모 언어 모델(LLM)의 도메인 특화 미세 조정 및 활용 방법에 대한 최신 연구 결과를 종합적으로 분석하고 평가합니다. 특히, 금융 분야를 중심으로 연구된 세 편의 논문 (Fine-tuning and Utilization Methods of Domain-specific LLMs, Domain-Driven LLM Development: Insights into RAG and Fine-Tuning …, The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An …)을 분석하여 LLM 미세 조정의 주요 과정, 장단점, 그리고 효과적인 활용 전략을 제시하고자 합니다. 본 보고서는 연구 결과를 바탕으로 LLM의 도메인 특화 적용에 대한 실질적인 시사점을 도출하고 향후 연구 방향을 제안합니다. 또한, 제공된 이미지들을 활용하여 LLM의 전반적인 맥락과 미세 조정 과정을 시각적으로 보여줍니다.
1. LLM 미세 조정의 현황과 과제
최근 몇 년 동안, 사전 훈련된 대규모 언어 모델(LLM)의 성능이 급격히 향상되었으며, 다양한 분야에서 활용되고 있습니다. 그러나 특정 도메인에 대한 LLM의 미세 조정 및 활용에 대한 연구는 아직 초기 단계에 있습니다 (Fine-tuning and Utilization Methods of Domain-specific LLMs). 특히 금융 분야와 같이 전문적인 지식과 높은 정확성이 요구되는 분야에서는 LLM의 효과적인 적용을 위한 미세 조정 방법론의 개발이 중요한 과제입니다. 기존의 일반적인 LLM은 특정 도메인의 전문 지식을 충분히 반영하지 못하여, 정확도와 신뢰성이 떨어질 수 있습니다. 따라서, 도메인 특화된 데이터를 활용한 미세 조정을 통해 LLM의 성능을 향상시키는 것이 필수적입니다.
그림 1: AI 개요 (출처: Adam Enfroy)
2. 도메인 특화 LLM 미세 조정 방법론
세 편의 연구 논문은 LLM의 미세 조정을 위한 다양한 방법론을 제시하고 있습니다. 특히, The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An …에서는 LLM 미세 조정을 위한 7단계 프로세스(데이터 준비, 모델 초기화, 학습 환경 설정, 미세 조정, 평가 및 검증, 배포, 모니터링 및 유지보수)를 상세히 설명합니다. 이 과정은 사전 훈련된 모델을 특정 작업에 적용하기 위한 매개변수 업데이트를 포함하며, 최적의 성능을 보장하기 위해 각 단계별 세심한 관리가 필요합니다.
Domain-Driven LLM Development: Insights into RAG and Fine-Tuning …에서는 Retrieval Augmented Generation (RAG)과 미세 조정 기법을 결합하여 LLM의 지식 범위를 확장하는 방법을 제시합니다. RAG는 LLM이 외부 지식 소스를 참조하여 답변을 생성하는 기술로, 미세 조정과 함께 활용하면 LLM의 성능을 더욱 향상시킬 수 있습니다. 특히, 사전 훈련 과정에서 다루지 않은 특정 도메인의 전문 지식을 효과적으로 학습하는 데 유용합니다. 이 연구는 RAG와 미세 조정의 장단점을 비교 분석하고, 각 방법론을 효과적으로 활용하기 위한 최선의 사례를 제시합니다.

그림 2: 모델 설명 가능성 vs. 모델 성능 (출처: ResearchGate)
3. 금융 분야에서의 LLM 활용 및 시사점
Fine-tuning and Utilization Methods of Domain-specific LLMs은 금융 분야에서 도메인 특화 LLM의 미세 조정 및 활용에 대한 연구를 제시합니다. 금융 분야는 복잡하고 전문적인 지식이 필요한 분야이기 때문에, 일반적인 LLM보다 도메인 특화된 LLM이 더욱 효과적일 수 있습니다. 이 연구는 금융 분야에 특화된 LLM을 미세 조정하고 활용하는 다양한 방법을 제시하며, 향후 금융 분야에서 LLM의 활용 가능성을 높일 수 있는 중요한 시사점을 제공합니다.
4. 결론 및 향후 연구 방향
본 보고서에서는 LLM의 도메인 특화 미세 조정 및 활용에 대한 최신 연구 동향을 분석하였습니다. 세 편의 연구 논문 분석 결과, 도메인 특화 데이터를 활용한 미세 조정과 RAG와 같은 기술을 결합하는 것이 LLM의 성능 향상에 중요한 역할을 한다는 것을 알 수 있었습니다. 특히, 금융 분야와 같은 전문적인 지식이 필요한 분야에서는 도메인 특화 LLM의 활용이 필수적이며, 미세 조정 과정의 각 단계별 세심한 관리가 성능 향상에 중요하게 작용합니다.
향후 연구는 다음과 같은 방향으로 진행될 수 있습니다: 다양한 도메인에서의 LLM 미세 조정 방법론 비교 연구, LLM의 설명 가능성 향상 연구, LLM의 윤리적 문제 및 안전성 확보 연구 등. 또한, 더욱 효율적이고 효과적인 미세 조정 기법 개발을 위한 연구가 지속적으로 필요합니다.
참고문헌
- Fine-tuning and Utilization Methods of Domain-specific LLMs. https://arxiv.org/abs/2401.02981
- Domain-Driven LLM Development: Insights into RAG and Fine-Tuning … https://dl.acm.org/doi/pdf/10.1145/3637528.3671445
- The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An … https://arxiv.org/html/2408.13296v2
(이미지 출처는 각 그림 아래에 명시되어 있습니다.)
지능형 문서 처리 시스템 평가 지표에 관한 보고서
서론
본 보고서는 지능형 문서 처리(Intelligent Document Processing, IDP) 시스템의 평가에 사용되는 지표 및 관련 연구 동향을 분석합니다. 최근 IDP 시스템의 발전과 함께, 시스템 성능을 정확하게 측정하고 비교하기 위한 객관적인 평가 지표의 중요성이 더욱 커지고 있습니다. 이 보고서에서는 기존 연구에서 제시된 다양한 평가 지표들을 검토하고, 새로운 평가 지표 개발의 필요성과 방향을 논의하며, 효과적인 IDP 시스템 평가를 위한 몇 가지 제언을 제시합니다. 본 보고서에 사용된 이미지들은 IDP 시스템의 다양한 응용 사례를 보여줍니다. ([Image 1: https://assets-global.website-files.com/64be86eaa29fa71f24b00685/64be86eaa29fa71f24b01054_668X375-10-Document-processing-tools.jpg][1], [Image 2: https://vue.ai/blog/wp-content/uploads/2023/07/Automated-Document-Processing-Solution.jpg][2], [Image 3: https://www.datamatics.com/hubfs/mobile-Datamatics-recognized-as-a-Major-Contender-Everest-Group-Intelligent-Document-Processing-Products-(IDP)-PEAK-Matrix-Asses.jpg][3], [Image 4: https://www.datamatics.com/hubfs/Tablet-Datamatics-recognized-as-a-Major-Contender-Everest-Group-Intelligent-Document-Processing-Products-(IDP)-PEAK-Matrix-Asses.jpg][4], [Image 5: https://planet-ai.com/wp-content/uploads/2023/07/Blog_07.25.2023_52-definitions-in-the-context-of-IDP_1-Metrics.png][5])
![https://assets-global.website-files.com/64be86eaa29fa71f24b00685/64be86eaa29fa71f24b01054_668X375-10-Document-processing-tools.jpg][1]](https://assets-global.website-files.com/64be86eaa29fa71f24b00685/64be86eaa29fa71f24b01054_668X375-10-Document-processing-tools.jpg%5D%5B1%5D){kind=link}
![https://vue.ai/blog/wp-content/uploads/2023/07/Automated-Document-Processing-Solution.jpg][2]](https://vue.ai/blog/wp-content/uploads/2023/07/Automated-Document-Processing-Solution.jpg%5D%5B2%5D){kind=link}
![https://www.datamatics.com/hubfs/mobile-Datamatics-recognized-as-a-Major-Contender-Everest-Group-Intelligent-Document-Processing-Products-(IDP)-PEAK-Matrix-Asses.jpg][3]](https://www.datamatics.com/hubfs/mobile-Datamatics-recognized-as-a-Major-Contender-Everest-Group-Intelligent-Document-Processing-Products-(IDP)-PEAK-Matrix-Asses.jpg%5D%5B3%5D){kind=link}
![https://www.datamatics.com/hubfs/Tablet-Datamatics-recognized-as-a-Major-Contender-Everest-Group-Intelligent-Document-Processing-Products-(IDP)-PEAK-Matrix-Asses.jpg][4]](https://www.datamatics.com/hubfs/Tablet-Datamatics-recognized-as-a-Major-Contender-Everest-Group-Intelligent-Document-Processing-Products-(IDP)-PEAK-Matrix-Asses.jpg%5D%5B4%5D){kind=link}
![https://planet-ai.com/wp-content/uploads/2023/07/Blog_07.25.2023_52-definitions-in-the-context-of-IDP_1-Metrics.png][5]](https://planet-ai.com/wp-content/uploads/2023/07/Blog_07.25.2023_52-definitions-in-the-context-of-IDP_1-Metrics.png%5D%5B5%5D){kind=link}
본론: 기존 연구 및 평가 지표
제공된 연구 결과를 살펴보면, IDP 시스템 평가에 대한 다양한 접근 방식이 존재함을 알 수 있습니다. 첫 번째 연구는 대규모 언어 모델(LLM) 워터마킹으로 인한 품질 저하를 포착하는 새로운 평가 지표를 제시합니다 (New Evaluation Metrics Capture Quality Degradation due to LLM Watermarking) [6]. 이 연구는 기존 지표의 한계를 보완하고, LLM 워터마킹의 부정적인 영향을 정량적으로 평가할 수 있는 새로운 지표를 제안합니다. 평가자의 판단 능력에 따라 점수 차이가 발생할 수 있지만, 특히 일관성 점수에서 큰 차이가 관찰되었습니다.
두 번째 연구는 표 처리 작업에서 사용되는 성능 지표를 조사합니다 (PDF) [7]. 재현율, 정밀도, 그리고 이들의 기하 평균인 F-측정치가 문서 및 표 처리 프로세스 평가에 일반적으로 사용되는 지표로 언급됩니다. 하지만 일반적으로 적합한 간결한 평가 지표가 부족하다는 점을 지적합니다. 이 연구는 다양한 평가 지표의 필요성을 강조하며, 더욱 포괄적이고 정확한 평가를 위한 지표 개발의 중요성을 시사합니다.
세 번째 연구는 문서 분석 시스템 평가를 위한 도구와 지표에 대해 논의합니다 (Tools and Metrics for Document Analysis Systems Evaluation) [8]. 이 연구는 스캔된 문서의 일반적인 내용과 노이즈에 맞춰 품질 지표를 조정해야 함을 강조합니다. 시스템, 모듈 또는 그 일부의 성능을 정량화하기 위해서는 객관적인 측정 기준인 지표가 필요하며, 이러한 지표는 시스템 전체 또는 모듈, 심지어 그 일부의 성능을 정량화하는 데 사용됩니다.
결론 및 제언
본 보고서에서 검토한 연구들은 IDP 시스템 평가를 위한 다양한 지표와 그 한계를 보여줍니다. 기존 지표들은 특정 상황에 적합할 수 있지만, 모든 상황에 적용 가능한 보편적인 지표는 아직 부족합니다. 따라서, 다양한 유형의 문서와 IDP 시스템의 특성을 고려한 새로운 평가 지표 개발이 필요합니다. 특히, LLM 워터마킹과 같은 새로운 기술적 요소를 고려한 평가 지표 개발이 중요하며, 평가자의 주관적인 판단을 최소화하고 객관성을 확보하는 방안을 모색해야 합니다. 또한, 다양한 평가 지표를 종합적으로 활용하여 시스템의 성능을 다각적으로 평가하는 접근 방식이 필요합니다. 향후 연구에서는 다양한 유형의 문서와 IDP 시스템에 대한 광범위한 실험을 통해 새로운 평가 지표의 유효성을 검증하고, 실제 시스템 구축 및 운영에 적용 가능한 실용적인 지표를 개발하는데 집중해야 할 것입니다.
참고문헌
[1] https://assets-global.website-files.com/64be86eaa29fa71f24b00685/64be86eaa29fa71f24b01054_668X375-10-Document-processing-tools.jpg [2] https://vue.ai/blog/wp-content/uploads/2023/07/Automated-Document-Processing-Solution.jpg [3] https://www.datamatics.com/hubfs/mobile-Datamatics-recognized-as-a-Major-Contender-Everest-Group-Intelligent-Document-Processing-Products-(IDP)-PEAK-Matrix-Asses.jpg [4] https://www.datamatics.com/hubfs/Tablet-Datamatics-recognized-as-a-Major-Contender-Everest-Group-Intelligent-Document-Processing-Products-(IDP)-PEAK-Matrix-Asses.jpg [5] https://planet-ai.com/wp-content/uploads/2023/07/Blog_07.25.2023_52-definitions-in-the-context-of-IDP_1-Metrics.png [6] New Evaluation Metrics Capture Quality Degradation due to LLM Watermarking. [7] PDF. [8] Tools and Metrics for Document Analysis Systems Evaluation.
{kind=link}
{kind=link}
-PEAK-Matrix-Asses.jpg){kind=link}
-PEAK-Matrix-Asses.jpg){kind=link}
{kind=link}
[최종 작성]
대규모 언어 모델(LLM) 전문 분야 미세 조정 후 문서 처리 능력 저하 원인 분석 보고서
서론
본 보고서는 대규모 언어 모델(LLM)을 특정 전문 분야나 기업/기관에 맞춰 미세 조정(fine-tuning)한 후, 문서 처리 능력이 기본 엔진 LLM에 비해 저하될 수 있는 근본 원인을 심층적으로 분석합니다. LLM의 미세 조정은 특정 도메인 지식을 효과적으로 학습시켜 성능을 향상시키는 중요한 과정이지만, 동시에 “재앙적 망각(Catastrophic Forgetting, CF)” 현상과 “일반 능력 통합(General Capabilities Integration, GCI)” 문제를 야기할 수 있습니다. 본 보고서는 제공된 연구 자료를 바탕으로 이러한 문제의 근본 원인을 탐색하고, 문서 처리 능력 저하의 메커니즘을 설명하며, 향후 연구 방향을 제시합니다. 특히, 미세 조정 과정에서 발생하는 과적합(overfitting), 지식 간섭(knowledge interference), 그리고 일반화 능력 저하(generalization degradation) 등의 요인에 초점을 맞춰 논의합니다.
1. 재앙적 망각(Catastrophic Forgetting)과 일반 능력 통합(GCI) 문제
LLM 미세 조정 과정에서 가장 큰 문제 중 하나는 재앙적 망각입니다. 이는 모델이 새로운 도메인에 대한 학습에 집중하면서 기존에 학습된 일반적인 지식이나 다른 도메인의 지식을 잊어버리는 현상을 말합니다 (Liu et al., 2024). 이러한 현상은 특히 문서 처리와 같이 다양한 언어적 이해와 지식을 필요로 하는 작업에서 치명적일 수 있습니다. 미세 조정된 LLM이 특정 전문 용어나 문맥에 과도하게 집중하면, 일반적인 문법, 어휘, 문맥 이해 능력이 저하될 수 있으며, 결과적으로 문서 처리의 정확성과 효율성이 떨어질 수 있습니다.
일반 능력 통합(GCI)은 재앙적 망각의 반대 개념으로, 특정 도메인에 대한 미세 조정 후에도 일반적인 언어 처리 능력을 유지하고 통합하는 능력을 의미합니다 (Liu et al., 2024). GCI가 부족하면 미세 조정된 LLM은 특정 도메인의 문서만 효과적으로 처리할 수 있고, 다른 유형의 문서를 처리하는 데는 어려움을 겪을 수 있습니다. 따라서, 문서 처리 시스템의 유연성과 확장성이 저하될 수 있습니다.
2. 과적합(Overfitting)의 문제
미세 조정 과정에서 과적합은 문서 처리 능력 저하의 주요 원인 중 하나입니다. 과적합은 모델이 훈련 데이터에 과도하게 적응하여 훈련 데이터에서는 높은 성능을 보이지만, 새로운 데이터(즉, 실제 문서)에 대해서는 성능이 저하되는 현상입니다 (Kolena, 2024). 특히, 전문 분야의 데이터가 제한적이거나 편향되어 있을 경우, 모델은 해당 데이터의 특징만을 과도하게 학습하여 일반화 능력이 떨어지게 됩니다. 이러한 과적합은 문서의 다양한 형식, 구조, 스타일, 어휘 등을 제대로 처리하지 못하게 만들어 문서 처리 능력의 저하로 이어집니다. 적절한 정규화 기법이나 데이터 증강 기법을 사용하지 않으면 이 문제가 심각해집니다.
3. 지식 간섭(Knowledge Interference)
미세 조정 과정에서 새로운 도메인 지식과 기존에 학습된 일반 지식 간의 간섭 또한 문서 처리 능력 저하에 영향을 미칩니다. 새로운 도메인의 특징과 기존 지식이 충돌하거나 모순될 경우, 모델은 이러한 지식들을 효과적으로 통합하지 못하고, 잘못된 판단이나 오류를 범할 수 있습니다. 예를 들어, 의료 분야에 미세 조정된 LLM이 일반적인 언어 표현과 의학 용어를 혼동하거나, 의학적 지식과 일반 상식이 충돌하는 경우에 잘못된 해석을 할 가능성이 있습니다. 이러한 지식 간섭은 문서의 의미 해석, 정보 추출, 요약 등의 작업에서 오류를 발생시켜 문서 처리 능력을 저하시킵니다.
4. 일반화 능력 저하(Generalization Degradation)
미세 조정된 LLM은 특정 도메인에 대한 성능은 향상될 수 있지만, 일반적인 언어 처리 능력은 저하될 수 있습니다. 이는 모델이 특정 도메인의 데이터에 과도하게 적응하여 다른 도메인의 데이터에 대한 적응력을 잃기 때문입니다 (Turing, 2024). 문서 처리 시스템은 다양한 유형의 문서를 처리해야 하므로, 일반화 능력의 저하는 시스템의 유용성을 크게 감소시킵니다. 미세 조정된 모델이 특정 형식이나 스타일의 문서에만 잘 작동하고, 다른 형식이나 스타일의 문서에는 성능이 떨어지는 현상이 발생할 수 있습니다.
5. 매개변수 효율적인 미세 조정(PEFT)의 한계
매개변수 효율적인 미세 조정(PEFT)은 전체 모델을 미세 조정하는 것보다 계산 비용과 메모리 사용량을 줄일 수 있는 효율적인 방법입니다 (DL4DS, 2024). 하지만 PEFT는 모든 경우에 최적의 성능을 보장하지는 않습니다. PEFT의 성능은 작업의 특성, 모델의 구조, 그리고 미세 조정 전략에 따라 달라지며, 부적절한 PEFT 전략은 오히려 문서 처리 능력을 저하시킬 수 있습니다. PEFT를 통해 미세 조정된 매개변수가 모델의 전체적인 성능에 부정적인 영향을 미칠 수 있으며, 특히 문서 처리와 같이 복잡한 작업에서는 더욱 그렇습니다.
6. 데이터 품질의 영향
미세 조정에 사용되는 데이터의 품질 또한 중요한 요인입니다. 데이터가 부정확하거나 불완전하거나, 편향되어 있다면, 모델은 잘못된 지식을 학습하고, 문서 처리 능력이 저하될 수 있습니다 (Label Your Data, 2024). 데이터 전처리 과정이 부실하거나, 데이터의 양이 부족하거나, 데이터의 다양성이 떨어지는 경우에도 문제가 발생할 수 있습니다. 특히 전문 분야의 데이터는 일반적으로 얻기 어렵고, 비용이 많이 들기 때문에, 데이터 품질 관리에 더욱 신경을 써야 합니다.
7. 결론 및 제언
본 보고서에서는 LLM을 특정 전문 분야에 미세 조정한 후 문서 처리 능력이 저하될 수 있는 여러 가지 근본 원인을 분석했습니다. 재앙적 망각, 과적합, 지식 간섭, 일반화 능력 저하, PEFT의 한계, 그리고 데이터 품질 문제 등이 문서 처리 능력 저하에 영향을 미치는 중요한 요인들입니다. 이러한 문제들을 해결하기 위해서는 다음과 같은 노력이 필요합니다.
- 균형 잡힌 미세 조정 전략: 특정 도메인 지식뿐만 아니라 일반적인 언어 처리 능력도 유지할 수 있는 균형 잡힌 미세 조정 전략을 개발해야 합니다.
- 과적합 방지 기술 적용: 정규화, 드롭아웃, 데이터 증강 등의 과적합 방지 기술을 적극적으로 활용해야 합니다.
- 데이터 품질 관리 강화: 정확하고, 완전하며, 다양한 데이터를 사용하고, 데이터 전처리 과정을 철저하게 수행해야 합니다.
- 지식 간섭 완화 기법 연구: 새로운 도메인 지식과 기존 지식 간의 간섭을 최소화하는 기법을 연구해야 합니다.
- **일반화 능력 향
상을 위한 연구:** 다양한 도메인의 데이터를 사용하여 모델의 일반화 능력을 향상시키는 연구가 필요합니다.
- PEFT 전략 최적화: 작업 특성과 모델 구조에 적합한 PEFT 전략을 선택하고 최적화해야 합니다.
지속적인 연구와 기술 개발을 통해 이러한 문제들을 해결하고, 특정 전문 분야에 맞춰 미세 조정된 LLM이 기존 LLM보다 더욱 우수한 문서 처리 능력을 발휘할 수 있도록 해야 합니다.
참고문헌
- Label Your Data. (2024). LLM Fine Tuning: The 2024 Guide for ML Teams.
- Turing. (2024). Fine-Tuning LLMs : Overview, Methods, and Best Practices.
- Kolena. (2024). LLM Fine-Tuning: Use Cases, Best Practices, and Top 8 PEFT Methods.
- DL4DS. (2024). Parameter Efficient Fine Tuning (PEFT) of LLMs.
- Liu, C., Kang, Y., Wang, S., Qing, L., Zhao, F., Wu, C., Sun, C., Kuang, K., Wu, F., Al-Onaizan, Y., Bansal, M., & Chen, Y. N. (2024). More Than Catastrophic Forgetting: Integrating General Capabilities For Domain-Specific LLMs.
(이미지 출처는 본문에 명시된 URL을 참고)